

The code that accompanies this article can be downloaded here.
In the previous article, we got familiar with reinforcement learning and the problem it is trying to solve. Reinforcement learning is the third paradigm or third type of learning in the universe of artificial intelligence. The other types of learning like supervised and unsupervised learning were covered on this site as well, so we decided to write a little bit about this completely different approach. In general, when we are talking about reinforcement learning we are talking about some type of interaction between self-learning agent and the environment.

The agent is trying to achieve some kind of goal inside of the environment while it interacts with it. The whole interaction is divided into time steps. In every time step, the agent performs certain actions, changes the state of the environment and based on the success of its action it gets a certain reward. This way the agent learns what actions should be performed an which shouldn’t in a defined environment state. The agent also associates values with each state. Basically, every state has a prediction of future rewards. Based on this information the agent creates a policy (maps state of the environment to the desired action) and value function (long-term goal of the agent). This approach is often split into separate episodes, like the separate games of chess, with reward only at the end of each episode. The whole process is simplified in the image below.

We also got familiar with the mathematical formalization of the previously mentioned process – Markov Decision Processes (MDPs). This framework gives us a formal description of the problem in which an agent seeks for the best policy, defined as the function π. Inside of the MDPs, we recognize several concepts, like a set of states – S, a set of actions – A, expected reward that agent will get going from one state to another – Ra(s, s’), etc. For more information about MDP, check this article.
There are two important concepts we need to emphasize. The first one is the value of a state s – Vπ(s) while following policy π. It is defined as the expected reward when starting in the state s:

where γ is the discount factor and it determines how much importance we want to give to future rewards. The second important concepts defined within this framework is the value of taking action a in state s under policy π. It is represented as an expected reward, that agent will get if it starts from state s, takes the action a and follows policy π – qπ(s, a) :

This is just the introduction of reinforcement learning. If you want to learn more you can check out our previous article. Anyhow, this is a rough representation of the problem. In this article, we will try to solve this problem by using Q-Learning, which is the simplest form of reinforcement learning.
Temporal-Difference Learning

Q-Learning is part of so-called tabular solutions to reinforcement learning, or to be more precise it is one kind of Temporal-Difference algorithms. These types of algorithms don’t model the whole environment and learn directly from environments dynamic. Apart from that, they update their estimates based on previous estimates, so they don’t wait for the final outcome of the process. The most simple form of Temporal-Difference is usually denoted as TD(0). It is presented with the mathematical formula:

where α is a learning rate. This means that this approach will wait until next time step t+1 and use reward and estimated value from that time step to update the value of the time step t. TD(0) is performed like this:
- Initialize value for each state from the set of states S arbitrary:
V(s) = n, ∀s ∈ S. - Pick the action a, from the set of actions defined for that state A(s) defined by the policy π.
- Perform action a
- Observe reward R and the next state s’
- Update value for the state using the formula:
V (s) ← V (s) + α [R + γV(s’) − V (s)] - Repeat steps 2-5 for each time step until the terminal state is reached
- Repeat steps 2-6 for each episode
As you can see this approach learn their estimates in part on the basis of other estimates. This is what more experienced artificial intelligence engineers like to call bootstrapping. It is referring to a situation in which the algorithm learns a guess from a guess. What does this have to do with Q-Learning? Well, Q-Learning is going one step further from Temporal-Difference Learning. In fact, they are not just learning how to guess from the other guess, but they are doing this regardless of the policy.
Q-Learning

As you could see Temporal-Difference Learning is based on estimated values based on the other estimations. Q-Learning is going one step further, it is estimating the aforementioned value of taking action a in state s under policy π – q. That is how it got its name. Basically, decisions of this approach are based on estimations of state-action pairs, not state-value pairs. The simplest form of it is called one-step Q-Learning and it is defined by the formula:
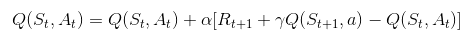
A Q-Value for a particular state-action combination can be observed as the quality of an action taken from that state. As you can see the policy still determines which state–action pairs are visited and updated, but nothing more. This is why Q-Learning is sometimes referred to as off-policy TD learning.
All these Q-Values are stored inside of the Q-Table, which is just the matrix with the rows for states and the columns for actions. This table is updated by the agent and looks something like this:

Let’s brake down Q-Learning into the steps:
- Initialize all Q-Values in the Q-Table arbitrary, and the Q value of terminal-state to 0:
Q(s, a) = n, ∀s ∈ S, ∀a ∈ A(s)
Q(terminal-state, ·) = 0 - Pick the action a, from the set of actions defined for that state A(s) defined by the policy π.
- Perform action a
- Observe reward R and the next state s’
- For all possible actions from the state s’ select the one with the highest Q-Value – a’.
- Update value for the state using the formula:
Q(s, a) ← Q(s, a) + α [R + γQ(s’, a’) − Q(s, a)] - Repeat steps 2-5 for each time step until the terminal state is reached
- Repeat steps 2-6 for each episode
After some time and enough random exploration of actions, the Q-Values tend to converge serving our agent as an action-value function we mentioned previously. The important thing to note is that sometimes we add additional constraint in order to stop overfitting. Basically, we use value epsilon which defines will we explore new actions and maybe come up with a better solution, or we will go with the already learned route. This parameter defines the relationship between the exploration of the new options and exploiting already learned options. Let’s now see how we can write a simple Python code for this approach.
Implementation

The code that accompanies this article can be downloaded here.
Prerequisites
In order to run this code, you have to have Python 3 installed on your machine. In this example, we are using Python 3.7. Also, you have to install Open AI Gym or to be more specific Atari Gym. You can install it by running:
pip install gym[atari]
If you are using Windows it is not this straight forward, so you can follow this article in order to properly install it.
Open AI Gym has its own API and the way it works. Since that is completely another topic, we will not go in depth of how interaction with the environment from the code is done. We will mention a few important topics as we go on that are important for understanding the code. However, we strongly suggest you can check out this article if you are not familiar with the concept and the API of Open AI Gym.
Environment
We’ll be using the Gym environment called Taxi-V2. This is one very simple environment, almost like ‘Hello world’ example. It was introduced to illustrate some issues in hierarchical reinforcement learning. In essence, there are 4 locations in the environment and the goal is to pick up the passenger at one location and drop him off in another. The agent can perform 6 actions (south, north, west, east, pickup, dropoff). You can find more information about it here.

Let’s see how we can solve it using Q-Learning.
Code
We will first import necessary libraries and modules:
| import numpy as np | |
| import random | |
| from IPython.display import clear_output | |
| import gym |
As you can see, we are importing numpy module – Python’s module for numerical operations and gym module – Open AI Gym library. Apart from that, we are using random and IPython.display for simple operations. Then we need to create an environment. That is done like this:
| enviroment = gym.make("Taxi-v2").env | |
| enviroment.render() | |
| print('Number of states: {}'.format(enviroment.observation_space.n)) | |
| print('Number of actions: {}'.format(enviroment.action_space.n)) |
We use the make function to instantiate an object of the environment we want. In this example, that is Taxi-v2 environment. We can display the current state of the environment and the agent with the render method. The important thing is that we can access all states of the environment using observation_space property and all actions of the environment using action_space. Here we have 500 states and 6 possible actions. Apart from these methods, Open Gym API has two more methods we need to mention. The first one is the reset method which resets the environment and returns a random initial state. Another one is the step method which steps the environment by one timestep and performs an action.
Now we can proceed with the training of the agent. Let’s first initialize necessary variables:
| alpha = 0.1 | |
| gamma = 0.6 | |
| epsilon = 0.1 | |
| q_table = np.zeros([enviroment.observation_space.n, enviroment.action_space.n]) |
Then we run the training using steps we mentioned in previous chapter:
| num_of_episodes = 100000 | |
| for episode in range(0, num_of_episodes): | |
| # Reset the enviroment | |
| state = enviroment.reset() | |
| # Initialize variables | |
| reward = 0 | |
| terminated = False | |
| while not terminated: | |
| # Take learned path or explore new actions based on the epsilon | |
| if random.uniform(0, 1) < epsilon: | |
| action = enviroment.action_space.sample() | |
| else: | |
| action = np.argmax(q_table[state]) | |
| # Take action | |
| next_state, reward, terminated, info = enviroment.step(action) | |
| # Recalculate | |
| q_value = q_table[state, action] | |
| max_value = np.max(q_table[next_state]) | |
| new_q_value = (1 – alpha) * q_value + alpha * (reward + gamma * max_value) | |
| # Update Q-table | |
| q_table[state, action] = new_q_value | |
| state = next_state | |
| if (episode + 1) % 100 == 0: | |
| clear_output(wait=True) | |
| print("Episode: {}".format(episode + 1)) | |
| enviroment.render() | |
| print("**********************************") | |
| print("Training is done!\n") | |
| print("**********************************") |
Note the epsilon value that we added in order to differentiate between expiration and exploration. The rest of the implementation is pretty much straight forward. Finally, we can evaluate the model we trained:
| total_epochs = 0 | |
| total_penalties = 0 | |
| num_of_episodes = 100 | |
| for _ in range(num_of_episodes): | |
| state = enviroment.reset() | |
| epochs = 0 | |
| penalties = 0 | |
| reward = 0 | |
| terminated = False | |
| while not terminated: | |
| action = np.argmax(q_table[state]) | |
| state, reward, terminated, info = enviroment.step(action) | |
| if reward == -10: | |
| penalties += 1 | |
| epochs += 1 | |
| total_penalties += penalties | |
| total_epochs += epochs | |
| print("**********************************") | |
| print("Results") | |
| print("**********************************") | |
| print("Epochs per episode: {}".format(total_epochs / num_of_episodes)) | |
| print("Penalties per episode: {}".format(total_penalties / num_of_episodes)) |
We can see that our agent performed without errors, meaning it picked up passengers and doped them off in the good location 100 times.
Conclusion
In this article, we got a chance to see how the simplest form of reinforcement learning Q-Learning is working. We explored how it all started and some math behind it. Apart from that, we had a chance to implement one simple example of Q-Learning using Python and Open AI gym. The problem with the Q-Learning is that as the number of states grows it becomes difficult to implement them with Q-Table. Today we are using an approach called Deep Q-Learning, which uses neural networks instead of the Q-table, but that is a topic for another article.
Thank you for reading!
Read more posts from the author at Rubik’s Code.



no idea if this is a real english article or a markov generated thing but put lightly i do not understand what the fuck it is on about
Sorry to hear that Dave, we tried to be as clear as possible.
You might want to try and read this article https://rubikscode.net/2019/06/17/introduction-to-reinforcement-learning/ before this one. Maybe that will help.
Anyhow, thank you for giving it a shot and reading it at all. We appriciate it!