

The code presented in this article can be found here.
In the previous articles, we explored how we can serve TensorFlow Models with Flask and how we can accomplish the same thing with Docker in combination with TensorFlow Serving. Both of these approaches utilized REST API. We were able to explore some good things regarding this approach. However, we also detected some shortcomings. The major ones are scalability and speed. In this article, we address both of those problems. Also, sometimes it feels unnatural to serve deep learning models with REST API because these are usually embedded within some kind of microservice. That is where gRPC comes into the picture. First, let’s get familiar with this technology and then we explore how we can use it in combination with TensorFlow Serving.
Eager to learn how to build Deep Learning systems using Tensorflow 2 and Python? Get the ebook here!

gRPC is Google’s open source RPC (Remote Procedure Call) framework. It is heavily used to connect services, across data centers, mobile application and other elements in distributed environments. Like any other RPC framework, main idea revolves around directly calling servers methods from the client, through some kind of service. Client calls these methods like it is accessing it’s local object. This is accomplished by first defining a service and implementing interface with gRPC server on the server side. Then these methods can be called using stub methods on the client side. This way we get a feeling that we are calling local client methods, while underneath we initiate gRPC communication between client and server.
gRPC and Protocol Buffers
gRPC uses protocol buffers as IDL (Interface Definition Language) underneath the hood. Protocol buffers are another Google’s open-source concept for serializing structured data in the communication protocols. Imagine something like XML, but faster and smaller. Since the main task of protocol buffers is the serialization of data, the first thing that we should do when we start using this technology is to define how our data is structured. This is done in .proto files, which is containing definitions of messages. Each message is composed of key-value pairs.

For example, if we want to define a message that defines a summary of some blog, it looks like this:
message BlogSummary{
required string name = 1;
required int32 number_of_articles = 2;
optional int32 number_of_authors = 3;
}Then we need to run protocol buffer compiler – protoc, for the programming language that we use in our application. This will generate code with classes for writing and reading data. Each field will get its ‘getters and setters‘. Here is Python usage example for the message described above:
BlogSummary blogSummary
blogSummary .set_name("Rubik's Code")
blogSummary .set_ number_of_articles (111)
blogSummary. number_of_ authors(3)This is a cool starting point, but gRPC goes one step further. It utilizes protoc, but it additionally generates the code for the server and the client. As we mentioned, in order to use gRPC, we first need to define a service. This is done in the .proto file with the service keyword. Let’s build complete .proto file for handling blogs. We call this service BlogKeeper. Here is what .proto file looks like:
syntax = "proto3";
option java_multiple_files = true;
option objc_class_prefix = "BLG";
package blogkeeper;
service BlogKeeper {
rpc GetInfo(Blog) returns (BlogSummary) {}
rpc ListArticles(Blog) returns (stream Article) {}
}
message Blog {
string name = 1;
}
message BlogSummary {
string name = 1;
int32 number_of_articles = 2;
int32 number_of_authors = 3;
}
message Article {
string title = 1;
string author = 2;
string category = 3;
}In this file we defined one service with BlogKeeper service and three messages: Blog, BlogSummary and Article. Note that service has defined two methods. They are defined with rpc keyword. In essence, there are four types of service methods:
- Unary RPC – These methods return a single response for a single request. They are defined like this: rpc SayHello(HelloRequest) returns (HelloResponse)
- Server Streaming RPC – These methods return multiple responses for a single request. They are defined like this: rpc LotsOfReplies(HelloRequest) returns (stream HelloResponse)
- Client Streaming RPC – These methods return a single response for a stream of requests. They are defined like this: rpc LotsOfGreetings(stream HelloRequest) returns (HelloResponse)
- Bidirectional streaming RPC – These methods stream responses for a stream of requests. They are defined like this: rpc BidiHello(stream HelloRequest) returns (stream HelloResponse)
It is important to note that connection to the gRPC Server is provided through gRPC Channel. gRPC uses HTTP/2, which is binary and it makes gRPC really fast.
gRPC vs REST API
Let’s pause for a second and let’s compare gRPC and REST API. You may notice certain similarities between the two, so let’s observe why we are considering changing the REST API. After all, it has been a major approach to building APIs on the web for a long time now. As you probably know, REST uses JSON and (usually) HTTP 1.1 for the communication, which makes it kinda big and slow. On the other hand gRPC uses light .proto files and HTTP/2. This puts gRPC in advantage.

Apart from that, the whole REST philosophy is quite complicated. If you want to make your API fully RESTflull, you would need to spend a lot of time and effort to do such a thing. That is why in practice, you deal with the services that support just a subset of rules defined by the REST philosophy. Thanks to the simple format of .proto files, gRPC is easy to define, utilize and understand. There is no additional theory behind it which makes it very pragmatic. It is also quite understandable and comes from basic programming language concepts. However, gRPC browser support is slim. gRPC lives in the back-end, in the world of the microservices.
At the moment it seems that gRPC will take over the world of the microservices and the other types of communication between services, while the REST will be used with the communication between UI back-end and the front-end.
Implementing gRPC
The code presented in this article can be found here.
Ok, we digressed there for a little while, so let’s get back to the implementation of gRPC. So, we finished our .proto file and now we need to run the compiler and generate the code for the client and the server. Since we use Python in this example, we first need to install gRPC. To do so, we use the command:
pip install grpcioApart from that, we need to install gRPC tools:
pip install grpcio-toolsOnce we completed this, we can run code generator from gRPC tools and use our .proto file:
python -m grpc_tools.protoc -I . --python_out=./blogkeeper --grpc_python_out=./blogkeeper \
blogkeeper.protoWe have run it from the folder where .proto file is located. Note that in this location we have created blogkeeper folder beforehand. As a result, we have two new files in that directory:
│ blogkeeper.proto
│
└───blogkeeper
blogkeeper_pb2.py
blogkeeper_pb2_grpc.pyThese two new file contains:
- All classes for the messages.
- All classes for the service.
- BlogKeeperStub class – This class can be be used on the client-side to invoke BlogKeeper RPCs.
- BlogKeeperServicer class – This class defines the interface for implementation of the BlogKeeper service.
- A function add_BlogKeeperServicer_to_server– This function adds a BlogkeeperServicer to a gRPC server.
So, now we have all the necessary elements to create both client and server-side for gRPC. Let’s start with the server.
gRPC Server Implementation
For the server-side, we want to read some sort of the database from which we can read data. We use SQL Server in this example. There we define the BlogDB database, with two tables: BlogSummary and Article. Here is what that looks like:
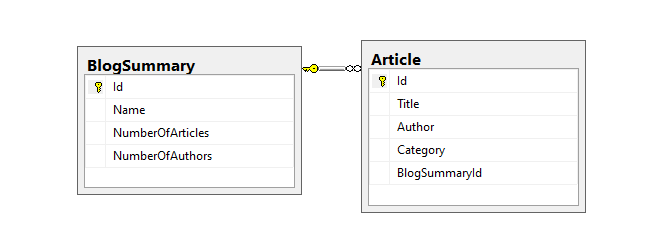
Also, we added some data in these tables. Ok, now when we have the data ready, we can create new file blogkeeprt_server.py in which we define BlogKeeperServer class. Here it is:
import logging
import pyodbc
import grpc
from concurrent import futures
import blogkeeper_pb2_grpc
import blogkeeper_pb2
class BlogKeeperServer(blogkeeper_pb2_grpc.BlogKeeperServicer):
def __init__(self):
self.db = pyodbc.connect('Driver={SQL Server};'
'Server=NZIVKOVIC\SQLEXPRESS;'
'Database=BlogDB;'
'Trusted_Connection=yes;')
def GetInfo(self, request, context):
cursor = self.db.cursor()
cursor.execute('SELECT * FROM [BlogDB].[dbo].[BlogSummary] \
where [Name] = \'{}\''.format(request.name))
response = blogkeeper_pb2.BlogSummary()
for data in cursor:
response.name = data[1]
response.number_of_articles = data[2]
response.number_of_authors=data[3]
return response
def ListArticles(self, request, context):
cursor = self.db.cursor()
cursor.execute('SELECT * FROM [BlogDB].[dbo].[Article] WHERE BlogSummaryId IN (SELECT Id \
FROM BlogSummary WHERE Name = \'{}\')'.format(request.name))
articles = []
for data in cursor:
article = blogkeeper_pb2.Article()
article.title = data[1]
article.author = data[2]
article.category = data[3]
articles.append(article)
yield article
def __del__(self):
self.db.close()
def serve():
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
blogkeeper_pb2_grpc.add_BlogKeeperServicer_to_server(BlogKeeperServer(), server)
server.add_insecure_port('[::]:50051')
server.start()
server.wait_for_termination()
if __name__ == '__main__':
logging.basicConfig()
serve()
This class inherits BlogKeeperServicer from the generated blogkeeper_pb2_grpc file. This inheritance drives our implementation since this class defines the interface that our server should provide. In the constructor of the server class, we connect to the instance of the database. Then we implement two methods GetInfo and ListArticles. If you recall, these were the methods we defined in .proto file as well. The implementation of these methods is straight forward. Based on the request we read information from the database, package it into response and send it back. In the end, we define serve function outside of the server class. In this method, we register the instance of the BlogKeeperServer object into gRPC server. Another cool thing we can do is define a number of workers on gRPC server. To run this server, we need to execute the command:
python .\blogkeeper\blogkeeper_server.pygRPC Client Implementation
Client class – BlogKeeperClient, is even easier. We implement it inside the blogkeeper_client.py file. Here is what it looks like:
import logging
import grpc
import blogkeeper_pb2
import blogkeeper_pb2_grpc
class BlogKeeperClient():
def __init__(self, ip_port):
channel = grpc.insecure_channel(ip_port)
self.stub = blogkeeper_pb2_grpc.BlogKeeperStub(channel)
def get_blog_summary(self, blog_name):
blog = blogkeeper_pb2.Blog(name=blog_name)
return self.stub.GetInfo(blog)
def get_list_of_articles(self, blog_name):
blog = blogkeeper_pb2.Blog(name=blog_name)
return self.stub.ListArticles(blog)
def run():
client = BlogKeeperClient('localhost:50051')
info = client.get_blog_summary('RubiksCode')
print('--------Blog Summary--------')
print(info)
print('----------------------------')
articles = client.get_list_of_articles('RubiksCode')
print('--------Articles-------')
for article in articles:
print(article)
print('----------------------')
if __name__ == '__main__':
logging.basicConfig()
run()Note that in the constructor we create gRPC channel and create an object of the BlogKeeperStub. This is the generated stub that was created in the blogkeeper_pb2_grpc file. In two methods, get_blog_summary and get_list_of_articles we just create Blog messages and call stub methods. These, in turn, call server methods through gRPC and get the information from the database. We also implement run method, which creates one client of BlogKeeperClient and calls the method. To run the client, execute this command:
python .\blogkeeper\blogkeeper_client.pyNow, if our server is running, here is what we get:
--------Blog Summary--------
name: "RubiksCode"
number_of_articles: 111
number_of_authors: 3
--------------------------
--------Articles-------
title: "Future of AI Healthcare"
author: "Nemanja Kovacev"
category: "AI in Healthcare"
--------------------------
title: "Top 7 TED Talks about Machine Learning"
author: "Marko Djapic"
category: "AI in Bussines"
--------------------------
title: "Deploying Deep Learning Models pt3"
author: "Nikola M. Zivkovic\t"
category: "AI"
-------------------------- gRPC with TensorFlow Serving
The code presented in this article can be found here.
Ok, now when we know what is gRPC and how to manipulate it, lets use it in the combination with TensorFlow Serving. Now, you might remember that in the previous article we deployed model for Iris Flower prediction using Docker and TensorFlow Serving. For that we used this command:
docker run -p 8500:8500 --mount type=bind, \
source="G:/deep_learning/deployment pt3/iris_predictor/model/1/", \
target=/models/saved_model/1 -e MODEL_NAME=saved_model -t tensorflow/servingAs you can see this opened two ports to our model, one for REST API on port 8501 and another one for gRPC on the port 8500. Notice that we bind to port 8500 of the localhost to the port 8500 of the Docker container in the command above. So, we already have our server-side up and running. Let’s create a gRPC client and utilize our model. We do that in the IrisPredictorClient class in the iris_predictor_client.py file. Here it is:
import grpc
import logging
import tensorflow as tf
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
class IrisPredictorClient(object):
def __init__(self, ip_port):
channel = grpc.insecure_channel(ip_port)
self.stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
def predict(self, input_data):
# Create request
request = predict_pb2.PredictRequest()
request.model_spec.name = 'saved_model'
# Fill inputs
request.inputs['dense_input'].CopyFrom(tf.make_tensor_proto(input_data, shape=[1, 4]))
return self.stub.Predict(request, 10.0)
def run():
client = IrisPredictorClient('127.0.0.1:8500')
prediction = client.predict([7.1, 3.0, 6.1, 2.3])
print('--------Prediction--------')
print(prediction)
print('----------------------------')
if __name__ == '__main__':
logging.basicConfig()
run()Notice that we use modules from tensorflow_serving.apis. Here we have generated generic request message classes and generic stub. In the constructor, we create stub using PredictionServiceStub and in the predict method, we use PredictRequest to create request messages. Make sure that you add a model name in the request object and make sure that your data is shaped in the correct format. Data is passed through the inputs of the request message and the name of the input should be the same as the name of the input layer of your model.
In the run function outside of the client class, we used first instance of the test Iris data, for which we know that the class is two. For more information about this data and model that we use in general take a look at this article. Once we run this script, output looks like this:
--------Prediction--------
outputs {
key: "dense_2"
value {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 1
}
dim {
size: 3
}
}
float_val: 1.5766686090046278e-07
float_val: 0.00013307273911777884
float_val: 0.9998667240142822
}
}
model_spec {
name: "saved_model"
version {
value: 1
}
signature_name: "serving_default"
}
----------------------------Note that we got three predictions and the one with the highest probability – class 2.
Conclusion
In this article, we covered a lot of ground. We described how gRPC functions in detail and how one can create an application that utilizes this technology. We saw how one can create .proto file, run the generator and use generated code to build server-side and client-side. Based on this knowledge, we implemented the client-side for the models that are served with TensorFlow Serving and got predictions from the model through gRPC.
Thank you for reading!

Nikola M. Zivkovic
CAIO at Rubik's Code
Nikola M. Zivkovic a CAIO at Rubik’s Code and the author of book “Deep Learning for Programmers“. He is loves knowledge sharing, and he is experienced speaker. You can find him speaking at meetups, conferences and as a guest lecturer at the University of Novi Sad.
Rubik’s Code is a boutique data science and software service company with more than 10 years of experience in Machine Learning, Artificial Intelligence & Software development. Check out the services we provide.



Trackbacks/Pingbacks