

In the previous article, we went through the basics of recommendation systems. We noted that there are four types of recommendation systems, of which two are the most popular. In this article, we are going to explore one of those popular approaches – Content-Based Recommendation Systems. As their name suggests, this type of recommendation system is focused on the content, ie. items that we want to suggest to the users of the platform we are building a recommendation system for. In order to achieve this and provide high-quality information, we use only information about items and their attributes. Essentially, this approach uses item features to recommend new items that are similar to the ones that the user has already liked or purchased and it doesn’t rely on the information about other users.
We don’t do sales, but given the circumstances and the severity of the situation, we decided to change that. Don’t be fooled, this sale isn’t meant for profit and it’s most definitely not planned. This sale is here to help people who want to become better, learn new skills and be more productive than ever before. Our book offers are on a 50% sale.

For example, let’s consider a platform similar to Netflix, in which a user can watch and rate movies and TV shows on a scale from 1 to 10. Imagine that there is a user which rated TV Show Modern Family with the rate 10. Would you recommend Peaky Blinders or Stranger Things to this user? Or maybe Brooklyn 9-9? It is most likely that we would suggest Brooklyn 9-9, because that is also a comedy. Technically, when we have a list of all TV shows in the corpus, we will recommend TV shows that are similar to each other. This means that we use some attributes to describe items in our system and based on the score of these features for each item we can calculate their similarity. If we use only two features (measures) to describe items in our example – comedy and sci-fi, tv shows like Brooklyn 9-9 would score high in the comedy, but low in sci-fi, while TV shows like Stranger Things would have a higher value in sci-fi than in comedy (even though this show is sometimes quite funny). Similarity can be calculated in different ways and in the previous article we explored cosine similarity, that we use in this article as well. This approach calculates the cosine value of the angle formed by the vectors of items in feature embedding space.
Content-Based Filtering Steps
At this point, you might wonder how exactly does this algorithm functions, so let’s go through the steps of it. First, let’s consider one user of the TV show platform we mentioned earlier and let’s assume that we have only six shows in the database. The rating scale is from 1 -10, ie. if a user rates a show with 1, she didn’t like that tv show at all and rating 10 would mean that she loved it. The user that we will examine rated shows like this:

She gave rating 10 to Modern Family, rating 2 to Peaky Blinders and rating 6 to Stranger Things. We can use this information to recommend the next show that this user should watch. First, we use genres and create a matrix that describes TV shows:

If movie belongs to a certain genre we put 1, otherwise, we put 0. Note that some TV Shows satisfy only one feature, while others have more. Also, you could use weighted values here as well. For example, you can say that Stranger Things on the sci-fi scale scores 0.7. We use just k-hot encoding for now. The next thing we do is represent the user using the same features by using the ratings she gave. To do this, we scale each feature by the user’s ratings and normalize it. As a result, we get the user features vector. To sum it up, steps for getting user features vector are:
- Multiply the movie feature matrix by user’s ratings
- Aggregate by summing across each feature dimension
- Normalize the result
In our example that would look something like this:

Interesting thing is that this user will have 0 for cartoons. Notice that this doesn’t mean that this user hates cartoons, but that it hasn’t seen one yet. This is why the sparsity of the data represents a big problem in recommendation systems. We can also see that for this user comedy seems to be a category that interests this user the most. This makes sense since this user liked Modern Family, so it goes well with our intuition. Whit this user feature vector, that describes the user’s affinities, we can calculate how a user would rate other TV Shows on the list. We just need to multiply this vector again with the TV-Show feature matrix (it’s transpose value to be more precise).
Ok, let’s scale this process to multiple users. Here is how that can be done with TensorFlow. First, we define arrays that contain users, TV shows and features:
users = ['Vanja', 'Vex', 'Peter', 'Angelina']
tv_shows = ['Modern Family', 'Peaky Blinders', 'La Casa de Papel', 'Rick and Morty', \
'Brooklyin 9-9', 'Stranger Things']
features = ['Action', 'Sci-Fi', 'Comedy', 'Cartoon', 'Drama']Then we define matrix that represents how each user ranked each tv show:
users_tv_shows = tf.constant([
[10, 2, 0, 0, 0, 6],
[5, 0, 9, 0, 4, 0],
[0, 7, 0, 10, 3, 0],
[0, 1, 0, 2, 10, 0]],dtype=tf.float32)We can see that the first user – Vanja is the one that we considered earlier. She liked Modern Family and disliked Peaky Blinders. Next, for each TV show we define features by creating matrix like this:
tv_shows_features = tf.constant([
[0, 0, 1, 0, 1],
[1, 0, 0, 0, 0],
[1, 0, 0, 0, 0],
[0, 1, 0, 1, 0],
[0, 0, 1, 0, 0],
[0, 1, 0, 0, 0]],dtype=tf.float32)In order to calculate user features vector we need to multiply these matrices and normalize them:
users_features = tf.matmul(users_tv_shows, tv_shows_features)
users_features = users_features/tf.reduce_sum(users_features, axis=1, keepdims=True)From here, we already can predict genre that each user likes the best:
top_users_features = tf.nn.top_k(users_features, num_feats)[1]
for i in range(num_users):
feature_names = [features[int(index)] for index in top_users_features[i]]
print('{}: {}'.format(users[i],feature_names))Here is the output:
Vanja: ['Comedy', 'Drama', 'Sci-Fi', 'Action', 'Cartoon']
Vex: ['Action', 'Comedy', 'Drama', 'Sci-Fi', 'Cartoon']
Peter: ['Sci-Fi', 'Cartoon', 'Action', 'Comedy', 'Drama']
Angelina: ['Comedy', 'Sci-Fi', 'Cartoon', 'Action', 'Drama']
We can see that Vanja and Angelina like Comedy, Vex likes Action and Peter like Sci-Fi. Based on this information we can predict the ratings of the shows that users haven’t seen yet. We do so by multiplying this users features matrix with transpose of TV shows features matrix:
users_ratings = tf.matmul(users_features, tf.transpose(tv_shows_features))The output of this operation is:
array([[0.71428573, 0.07142857, 0.07142857, 0.21428572, 0.35714287,
0.21428572],
[0.6086956 , 0.39130434, 0.39130434, 0. , 0.39130434,
0. ],
[0.1 , 0.23333333, 0.23333333, 0.6666667 , 0.1 ,
0.33333334],
[0.6666667 , 0.06666667, 0.06666667, 0.26666668, 0.6666667 ,
0.13333334]], dtype=float32)>Finaly, we can remove tv shows that user already saw and make one recommendation by taking the maximal value from the remaining shows.
users_unseen_tv_shows = tf.equal(users_tv_shows, tf.zeros_like(users_tv_shows))
ignore_matrix = tf.zeros_like(tf.cast(users_tv_shows, tf.float32))
users_ratings_new = tf.where(
users_unseen_tv_shows,
users_ratings,
ignore_matrix)
top_movies = tf.nn.top_k(users_ratings_new, 1)[1]
If we make that output more pretty:
for i in range(num_users):
movie_names = [tv_shows[index] for index in top_movies[i]]
print('{}: {}'.format(users[i], movie_names))Here are the recommendations for each user:
Vanja: ['Brooklyin 9-9']
Vex: ['Peaky Blinders']
Peter: ['Stranger Things']
Angelina: ['Modern Family']Content-Based Recommendation Systems with TF-IDF
This seems pretty easy, however, when we are faced with real data this approach can be improved. Especially if we have a lot of data. In this example, we consider the Movie Lense dataset, provided by GroupLense. This dataset is a common education and practice dataset. It contains a database of movies, their genres (i.e. features) and users ratings of those movies. You can download the latest version here (download ml-lates.zip and unzip it). This dataset describes 5-star rating and free-text tagging activity from a movie recommendation service – MovieLens. There are 27753444 ratings, 1108997 tag applications for 58098 movies and 283228 users. The data is located in files:
- genome-scores.csv
- genome-tags.csv
- links.csv
- movies.csv
- ratings.csv
- tags.csv
Tag relevance scores for movies are contained in special data structures called tag genome, i.e each movie in the genome has a value for every tag in the genome. The tag genome encodes how strongly some movie and attribute is related. These attributes represented by tags (atmospheric, thought-provoking, realistic, etc.).

TF-IDF Intuition
So, what is the TF-IDF algorithm? This algorithm is first developed for search purposes, but it can be used for anything. At the moment, TF-IDF is used by search engines to better understand the content that is undervalued. It weighs a keyword (term) in any document and calculates its importance. This is done based on the number of times defined keyword appears in the document. It sounds complicated, but in reality, it is not. We use two metrics TF and IDF. The first one – TF or term frequency represents the frequency of certain keyword appears in a document. It is calculated like this:
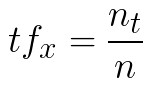
where x is the keyword, nt is the number of times x appears in the document and n is the total number of words in the document.
The other metric Inverse Document Frequency or IDF measures how important is the keyword in the complete corpus of word. It is calculated with this formula

where x is the keyword, N is the total number of documents and dfx is the number of documents with keyword x in it.
Finally, we calculate the TF-IDF coefficient by multiplying these values. Keywords with high TF-IDF words are rare and significant. The cool thing is that sci-kit learn provides this function out of the box. Ok, but why do we need this? Well, we will use it to the representation of every movie in terms of its description, meaning in terms of its genre.
Loading and Preparing Data
Ok, now we know all the algorithms that we use, we can load data and pre-process it. We do so with DataHandler class:
class DataHandler():
def __init__(self, data_location):
self._load_data(data_location)
self._merge_tags_scores()
self._filter_tags()
self._encode_features()
self._average_rating_per_movie()
self._build_dataset()
def _load_data(self, data_location):
self.movies = pd.read_csv(f'{data_location}/movies.csv')
self.links = pd.read_csv(f'{data_location}/links.csv')
self.ratings = pd.read_csv(f'{data_location}/ratings.csv')
self.genome_tags = pd.read_csv(f'{data_location}/genome-tags.csv')
self.genome_scores = pd.read_csv(f'{data_location}/genome-scores.csv')
def _merge_tags_scores(self):
self.tags_scores = pd.merge(self.genome_scores, self.genome_tags, on='tagId') \
[['movieId', 'tag', 'relevance']]
def _filter_tags(self, treshold = 0.3):
self.tags = self.genome_scores[self.genome_scores.relevance > 0.3][['movieId', 'tagId']]
def _encode_features(self):
self.tags_to_movies = pd.merge(self.tags, self.genome_tags, on='tagId', how='left') \
[['movieId', 'tagId']]
self.tags_to_movies['tagId'] = self.tags_to_movies.tagId.astype(str)
self.tags_per_movie = \
self.tags_to_movies.groupby('movieId')['tagId'].agg(self._concatenate_tags)
self.tags_per_movie.name = 'movie_tags'
self.tags_per_movie = self.tags_per_movie.reset_index()
def _concatenate_tags(self, tags):
return ' '.join(set(tags))
def _average_rating_per_movie(self):
self.avg_ratings = self.ratings.groupby('movieId')['rating'].agg(['mean', 'median', 'size'])
self.avg_ratings.columns = ['rating_mean', 'rating_median', 'num_ratings']
self.avg_ratings = self.avg_ratings.reset_index()
self.movies_with_ratings = pd.merge(self.movies, self.avg_ratings, how='left', on='movieId')
def _build_dataset(self):
self.dataset = pd.merge(self.movies_with_ratings, self.tags_per_movie, how='left', \
on='movieId')
self.dataset = self.dataset[~self.dataset.movie_tags.isnull()].reset_index(drop=True)
def get_tags_for_movie(self, movieId):
return self.tags[self.tags['movieId'] == movieId].merge(self.genome_tags, \
on='tagId').sample(10)
def get_average_rating_for_movie(self, movieId):
return self.movies_with_ratings[self.tags['movieId'] == movieId]
def get_movie_info(self, movieId):
return self.dataset[self.dataset['movieId'] == movieId]
def get_movies_with_title(self, title):
return self.dataset[self.dataset.title.str.contains(title)]
It is a big class, but quite simple. Most of the logic happens in the constructor of the class. First, we load data from all CSV files in data_location. This is done in the _load_data method. Then genome tags and genome tag scores are merged and only tags with a score above the defined threshold are used. We use the threshold 0.3 as a default. After that, features are encoded, meaning every movie is connected with its tags, which are converted into a united string. This way we can apply TF-IDF to tags. In the end, we create the dataset by merging the average rating per movie with tags. This class has four public methods:
- get_tags_for_movie – returns tags for movie.
- get_average_rating_for_movie – returns average rating for a movie.
- get_movie_info – returns information about the movie based on the movie IDF.
- get_movie_info_with_title – returns information about the movies based on the movie title.
Here is how this class can be used. For example, I really like movie Snatch, so I want to find information about it in the dataset:
dataHandler = DataHandler('./data')
snatch_movies = dataHandler.get_movies_with_title('Snatch')As an output I get a list of all movies that have word snatch in their title:

I can see that the movie I am looking for has ID 4011, so I call this function to get information about this movie:
snatch_tags = dataHandler.get_tags_for_movie(4011)
TF-IDF Implementation
For the TF-IDF we use class TFIDF. Here it is:
class TFIDF():
def __init__(self, dataset):
tf_idf = TfidfVectorizer()
self.dataset = dataset
self.dataset_transformed = tf_idf.fit_transform(dataset.movie_tags)
self.movie_similarities = cosine_similarity(self.dataset_transformed)
self.tfidf_similarities = pd.DataFrame(cosine_similarity(self.dataset_transformed))
index_to_movie_id = dataset['movieId']
self.tfidf_similarities.columns = [str(dataset['movieId'][int(col)]) \
for col in self.tfidf_similarities.columns]
self.tfidf_similarities.index = [dataset['movieId'][idx] for idx in \
self.tfidf_similarities.index]
def find_top_5_simmilar_movies(self, movieId):
index = self.dataset.index[self.dataset['movieId'] == movieId]
simmilar_movies = self.tfidf_similarities.iloc[index].transpose().sort_values(by=4011, \
ascending=False)[1:6]
return self.dataset[similarities.dataset['movieId'].isin(simmilar_movies.index.values)].titleAll important things are done in the constructor. We use tf_idf from sci-kit learn to get extend dataset with descriptions based on tags. Also, we calculate the cosine similarity between each movie. Matrix movie_similarities contains information about how each movie relates to other movie based on the tags. This class provides one method find_top_5_simmilar_movies. This method returns 5 similar movies based on the movie Id. Here is how I can use this class to get movies that are similar to Snatch:
similarities = TFIDF(dataHandler.dataset)
similarities.find_top_5_simmilar_movies_titles(4011)As the output we get:
283 Pulp Fiction (1994)
989 Reservoir Dogs (1992)
2278 Lock, Stock & Two Smoking Barrels (1998)
8597 Departed, The (2006)
9159 In Bruges (2008)Wow, that is really cool. Those movies are really similar to Snatch.
User Profiling
Finally, we need to profile each used, get her affinities and suggest similar movies based on that. We do that using UserProfiler class:
class UserProfiler():
def __init__(self, tfidf, dataHandler):
self.dataHandler = dataHandler
self.tfidf = tfidf
def get_user_ratings(self, userId):
user_ratings = self.dataHandler.ratings[self.dataHandler.ratings.userId == userId]
return self.dataHandler.dataset.reset_index().merge(user_ratings, on='movieId') \
[['title', 'rating']]
def get_user_recommendations(self, userId):
user_ratings = self.get_user_ratings(userId)
user_ratings['weight'] = user_ratings['rating']/5.
profile = np.dot(self.tfidf.dataset_transformed[user_ratings.index.values].toarray().T, \
user_ratings['weight'].values)
cos_sim = cosine_similarity(np.atleast_2d(profile), self.tfidf.dataset_transformed)
recs = np.argsort(cos_sim)[:, ::-1]
recommendations = [i for i in recs[0] if i not in user_ratings.index.values]
return self.dataHandler.dataset['title'][recommendations]This class puts all together. It provides two methods get_user_ratings and get_user_recommendations. Here is how to use it to create recommendations for a user with ID 111:
recomender = UserProfiler(similarities, dataHandler)
recomender.get_user_ratings(111).sort_values(by='rating', ascending=False)
recomender.get_user_recommendations(111).head()Finally here is the output:
13106 Coco (2017)
13100 Three Billboards Outside Ebbing, Missouri (2017)
13157 Isle of Dogs (2018)
13168 A Quiet Place (2018)
13006 13 reasons whyConclusion
In this article, we explored how Content-Based Filtering works. For some recommendation systems, you will not need more than this technique, while for the others this is a perfect place to start and gather more data about the users. The main advantage is that only has to analyze the items and a single user’s profile, which makes it fairly simple to implement and it is not demanding when it comes to processing power. If we don’t have many users in the system, it will give pretty good results. Apart from that, it eliminates cold start problems. However, these systems can be imprecise exactly because it is not taking into consideration the behavior of other users in the system. For the same reason, it can over-specialize which leads to less diverse and novel recommendations.
Thank you for reading!

Nikola M. Zivkovic
CAIO at Rubik's Code
Nikola M. Zivkovic a CAIO at Rubik’s Code and the author of book “Deep Learning for Programmers“. He is loves knowledge sharing, and he is experienced speaker. You can find him speaking at meetups, conferences and as a guest lecturer at the University of Novi Sad.
Rubik’s Code is a boutique data science and software service company with more than 10 years of experience in Machine Learning, Artificial Intelligence & Software development. Check out the services we provide.



Interesting! I though whether the descriptive sparse matrix mentioned at the beginning is accurate. I assume this is just simple example in reality there is a lot more dimensions an a show is not rated only by one janer.
Hey, thanks for reading! Yeah, it is just descriptive example. In essence, it is up to you to describe items in terms you see fit. Ussually there are more features, however, the principles are the same.