

As a person coming from .NET world, it was quite hard to get into machine learning right away. One of the main reasons was the fact that I couldn’t start Visual Studio and try out these new things in the technologies I am proficient with. I had to solve another obstacle and learn other programming languages more fitting for the job like Python and R. You can imagine my happiness when more than a year ago, Microsoft announced that as a part of .NET Core 3, a new feature will be available – ML.NET.
In fact it made me so happy that this is the third time I write similar guide. Basically, I wrote one when ML.NET was a version 0.2 and one when it was version 0.10. Both times, guys from Microsoft decided to modify the API and make my articles obsolete. That is why I have to do it once again. But hey, third time is the charm, so hopefully I will not have to do this again until ML.NET 2.0 🙂 Anyhow, with .NET Core 3 we got a new toy to play around. With this tool we are able to build and test machine learning models in .NET world on our own computers.
Actually, I gave a talk at local Microsoft conference – Tarabica about this technology and the main question was “Why should we use this one instead of Python and TensorFlow?”. In general, there is no specific reasons to go this way except the technology stack. If you are having ASP.NET application with the request for machine learning module, you will integrate the ML.NET one much easier. Also, now you can load modules that you have built with TensorFlow into ML.NET.
Why Machine Learning?

Before we continue with the task at hand, let’s just take a moment and reflect on why is Microsoft introducing this technology now and why should we care about it. There are few reasons we need to consider. First one is that the technology is crossing the chasm. This term means that technology is moving from the period where this was practiced only by the few to a place where it is no longer a novelty. That is true for the machine learning as well, since today we can build our own machine learning models for real problems on home computer. Python and TensorFlow are one step ahead of others and are favorite technology combo. Microsoft didn’t enter the game thus far. They provided CTK and Azure Machine Learning for cloud-based analytics, but they never seemed to take off. At least not in the way that TensorFlow did.

The other reason why you should start exploring this magnificent field is the fact that we, as a human race, produce a lot of data. Individually we are not able to process that much data and even less make the science of it all. Technically, we are facing with the problem that we can not extract information from the data. We can not see the forest from the trees if you will. However, machine learning models can. The statistics say that from the beginning of time up until 2005. humans have produced 130 Exabytes of data. Exabyte is a real word, by the way, I’ve checked. That is 1018 bytes of data.
What is interesting is that from that from that point in time up until 2010. we produced 1200 exabytes of data, thanks to the increase number of devices connected to the WEB. Until 2015. this number increased to 7900 exabytes of data. Predictions are telling us that by 2025. we will produce 193 Zettabytes of data. Now that is a lot (A LOT) of data. Using machine learning models we make practical use of it.
I like to observe the whole machine learning field as weird steampunk science. This is because we are innovating more in the field than ever before. Basically, all the main concepts we today are based on some “ancient” knowledge. Byes theorem was presented in 1763, and Markov’s chains in 1913. The idea of a learning machine can be traced back to the 50s, to the Turing’s Learning Machine and Frank Rosenbllat’s Perceptron. Meaning, we have 50+ years of piled knowledge to support us in our shenanigans. To sum it up, we are at a specific point in history, where we have a lot of knowledge, we have a lot of data and we have the technology. Let’s use that opportunity and these tools as best as we can.
Learning Machines

Machine Learning is a branch of computer science that uses statistical techniques to give computers the ability to learn how to solve certain problems without explicitly programming it. As mentioned, all important machine learning concepts can be traced back to the 1950s. The main idea, however, is to develop a mathematical model which will be able to make some predictions. This model is usually trained on some data beforehand.
In a nutshell, the mathematical model uses insights made on old data to make predictions on new data. This whole process is called predictive modeling. If we put it mathematically we are trying to approximate a mapping function – f from input variables X to output variables y. There are two big groups of problems we are trying to solve using this approach: Regression and Classification.
Regression problems require prediction of the quantity. This means our output is continuous, real-value, usually an integer or floating point value. For example, we want to predict the price of the company shares based on the data from the past couple of months. Classification problems are a bit different. They are trying to divide an input into certain categories. This means that the output of this tasks is discrete. For example, we are trying to predict the class of fruit on its dimensions. In this article, we will consider one real-world regression problem solve it with ML.NET.
Types of Learning

There are three ways machines can learn how to perform certain task:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
In supervised learning, an agent learns how to map certain inputs to some output. The agent learns how to do that because during the learning process it is provided with training inputs and labeled expected outputs for those inputs. Using this approach we are able to solve many types of problems, mostly the ones which are classification and regression problems in nature. This is an important type of learning and it is mostly used commercial approach today and the type of learning we will examine in this article with ML.NET.

Another type of learning is unsupervised learning. In this type of learning, the agent is provided only with input data, and it needs to make some sort of sense out of it. The agent is basically trying to find patterns in otherwise unstructured data. This type of problem is usually used for classification or cauterization types of problems.
The third paradigm of machine learning is called reinforcement learning. This type of learning implies an interaction between the learning agent and its environment. The agent tries to achieve a defined goal within that environment. Every action of the agent sets the environment in a different state and affects future options and opportunists for the agent. Since the effects of action cannot be predicted, because of the uncertainty of the environment, the agent must monitor it. Many papers actually consider that this type of learning is the future of AI. This might be true if you consider that this is a tool of natural selection.
Building a Machine Learning Model

In general, there are several steps we can follow when we are building a machine learning model. Here there are:
- Data Analysis
- Applying Proper Algorithm
- Evaluation
At the moment, ML.NET is not giving us too many options when it comes to the Data Analysis area, so in these examples, I will use Python to get information that I need. This is probably the only thing that I don’t like about ML.NET, since this step is crucial when it comes to creating machine learning model. Python and R are far ahead regarding this topic, so it is left for us to see will .NET catch up with them. Data Analysis is consisting of several sub-steps itself and more details about it can be found here.
Using information from this analysis we can take appropriate actions during the model creation. ML.NET is giving us a lot of precooked algorithms and means to use them quickly. Also, it is easy to tune each of these mechanisms. In this article, I will try to use as many algorithms as possible, but I will not go in depth and explain them in details. Another note is that I will use only the default setups of these algorithms. Take into consideration that you can get better results if you tune them up differently.
Installing ML.NET

If you want to use ML.NET in your project, you need to have at least .NET Core 3.0, so make sure you have it installed on your computer. The other thing you should know is that it currently must run in the 64-bit process. Keep this in mind while making your .NET Core project. Installation is pretty straight forward with Package Manager Console. All you have to use is the command:
Install-Package Microsoft.ML
This can be achieved with .NET Core CLI as well. If you are going to do it this way, make sure you have installed .NET Core SDK and run this command:
dotnet add package Microsoft.ML
Alternatively, you can use Visual Studio’s Manage NuGetPackage option:

After that, search for Microsoft.ML and install it.
Regression Problem

Bike sharing systems work like rent-a-car systems, but for bikes. Basically, a number of locations in the city are provided where the whole process of obtaining a membership, renting a bicycle and returning it is automated. Users can rent a bicycle in one location and return it to a different location. There are more than 500 cities around the world with these systems at the moment.
The cool thing about these systems, apart from being good for the environment, is that they record everything that is happening. When this data is combined with weather data, we can use it for investigating many topics, like pollution and traffic mobility. That is exactly what we have on our hands in Bike Sharing Demands Dataset. This dataset is provided by the Capital Bikeshare program from Washington, D.C.
This dataset has two files, one for the hourly (hour.csv) records and the other for daily (day.csv) records. This data is collected between 2011. and 2012. and it contains corresponding weather and seasonal information.
In this article, we will use only hourly samples. Here is how they look like:

The hour.csv file contains following features (attributes):
- Instant – sample index
- Dteday – Date when the sample was recorded
- Season – Season in which sample was recorded
- Spring – 1
- Summer – 2
- Fall – 3
- Winter – 4
- Yr – Year in which sample was recorded
- The year 2011 – 0
- The year 2012 – 1
- Mnth – Month in which sample was recorded
- Hr – Hour in which sample was recorded
- Holiday – Weather day is a holiday or not (extracted from [Web Link])
- Weekday – Day of the week
- Workingday – If the day is neither weekend nor holiday is 1, otherwise is 0.
- Weathersit – Kind of weather that was that day when the sample was recorded
- Clear, Few clouds, Partly cloudy, Partly cloudy – 1
- Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist – 2
- Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds – 3
- Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog – 4
- Temp – Normalized temperature in Celsius.
- Atemp – Normalized feeling temperature in Celsius.
- Hum – Normalized humidity.
- Windspeed – Normalized wind speed.
- Casual – Count of casual users
- Registered – Count of registered users
- Cnt – Count of total rental bikes including both casual and registered
In this article, the analysis of the data is not done. However, we already have an article on our site that does just that! Feel free to check it out.
Implementation

Ok, we are finally here. The solution we are going to present here is not just creating one machine learning model. We are going to run several regression algorithms from ML.NET on this dataset and evaluate which one worked the best. The whole code that accompanies this article can be found here.
Handling Data
There is one technicality that needs to be done before implementing the solution. The usual practice is to divide the presented dataset into a training set and testing set. This way we can evaluate our model without fear that it is biased. Another usual practice is that 80% of data goes into the training set and 20% to the testing set. However, you can use different ratio if it better suites your data.
Here is how one of these files look like:

Once we separated data into these sets we need to create classes that can handle them. Two classes: BikeSharingDemandSample and BikeSharingDemandPrediction located in BikeSharingDemandDatafolder are used for that. Objects of these classes will handle information from .csv files. Take a look at the way they are implemented:
| using Microsoft.ML.Data; | |
| namespace BikeSharingDemand.BikeSharingDemandData | |
| { | |
| public class BikeSharingDemandSample | |
| { | |
| [LoadColumn(2)] public float Season; | |
| [LoadColumn(3)] public float Year; | |
| [LoadColumn(4)] public float Month; | |
| [LoadColumn(5)] public float Hour; | |
| [LoadColumn(6)] public bool Holiday; | |
| [LoadColumn(7)] public float Weekday; | |
| [LoadColumn(8)] public float Weather; | |
| [LoadColumn(10)] public float Temperature; | |
| [LoadColumn(12)] public float Humidity; | |
| [LoadColumn(13)] public float Windspeed; | |
| [LoadColumn(14)] public float Casual; | |
| [LoadColumn(16)] public float Count; | |
| } | |
| public class BikeSharingDemandPrediction | |
| { | |
| public float Score { get; set; } | |
| } | |
| } |
The important thing to notice is that some features are not on the list, ie. we skipped some of the columns from the dataset. This is done based on data analysis that we previously have done. We removed the dtedate feature since this information is located in other features, like day and hour. Registered and casual features are removed too. Another thing that you should note is that in prediction class BikeSharingDemandPrediction output property must be decorated with ColumnName(“Score“) attribute.
Building the Model
The whole process of creating a model and generating predictions is located inside of the Model class. This class is used as a wrapper for all the operations we want to perform. Here is how it looks like:
| using BikeSharingDemand.BikeSharingDemandData; | |
| using Microsoft.ML; | |
| using Microsoft.ML.Data; | |
| using System.Linq; | |
| namespace BikeSharingDemand.ModelNamespace | |
| { | |
| public sealed class Model | |
| { | |
| private readonly MLContext _mlContext; | |
| private IDataView _trainingDataView; | |
| private IEstimator<ITransformer> _algorythim; | |
| private ITransformer _trainedModel; | |
| private PredictionEngine<BikeSharingDemandSample, BikeSharingDemandPrediction> _predictionEngine; | |
| public string Name { get; private set; } | |
| public Model(MLContext mlContext, IEstimator<ITransformer> algorythm, string trainingDataLocation) | |
| { | |
| _mlContext = mlContext; | |
| _algorythim = algorythm; | |
| _trainingDataView = _mlContext.Data.LoadFromTextFile<BikeSharingDemandSample>( | |
| path: trainingDataLocation, | |
| hasHeader: true, | |
| separatorChar: ','); | |
| Name = algorythm.GetType().ToString().Split('.').Last(); | |
| } | |
| public void BuildAndFit() | |
| { | |
| var pipeline = _mlContext.Transforms.CopyColumns(inputColumnName: "Count", outputColumnName: "Label") | |
| .Append(_mlContext.Transforms.Categorical.OneHotEncoding("Season")) | |
| .Append(_mlContext.Transforms.Categorical.OneHotEncoding("Year")) | |
| .Append(_mlContext.Transforms.Categorical.OneHotEncoding("Holiday")) | |
| .Append(_mlContext.Transforms.Categorical.OneHotEncoding("Weather")) | |
| .Append(_mlContext.Transforms.Concatenate("Features", | |
| "Season", | |
| "Year", | |
| "Month", | |
| "Hour", | |
| "Weekday", | |
| "Weather", | |
| "Temperature", | |
| "Humidity", | |
| "Windspeed", | |
| "Casual")) | |
| .Append(_mlContext.Transforms.NormalizeMinMax("Features", "Features")) | |
| .AppendCacheCheckpoint(_mlContext) | |
| .Append(_algorythim); | |
| _trainedModel = pipeline.Fit(_trainingDataView); | |
| _predictionEngine = _mlContext.Model.CreatePredictionEngine<BikeSharingDemandSample, BikeSharingDemandPrediction>(_trainedModel); | |
| } | |
| public BikeSharingDemandPrediction Predict(BikeSharingDemandSample sample) | |
| { | |
| return _predictionEngine.Predict(sample); | |
| } | |
| public RegressionMetrics Evaluate(string testDataLocation) | |
| { | |
| var testDataView = _mlContext.Data.LoadFromTextFile<BikeSharingDemandSample>( | |
| path: testDataLocation, | |
| hasHeader: true, | |
| separatorChar: ',', | |
| allowQuoting: true, | |
| allowSparse: false); | |
| var predictions = _trainedModel.Transform(testDataView); | |
| return _mlContext.Regression.Evaluate(predictions, "Label", "Score"); | |
| } | |
| public void SaveModel() | |
| { | |
| _mlContext.Model.Save(_trainedModel, _trainingDataView.Schema, "./BikeSharingDemandsModel.zip"); | |
| } | |
| } | |
| } |
As you can see, it is one quite large class. Let’s explore some of it’s main parts. This class has four private fields:
- _mlContext – This field contains MLContext instance. This concept is similar to the DbContext when EntityFramework is used.
MLContext provides a context for your machine learning model. - _traningDataView – Data prepared for processing.
- _algorythim – This field contains an algorithm that will be used in our model. This value is injected into the Model class.
- _trainedModel – This field contains a machine learning model after it is trained with the training set.
- _predictionEngine – This field contains PredictionEngine using which we are able to run predictions on a single sample.
Most of these fields are initialized in the constructor. In the constructor of this class, we initialize injected parameters, but we load the data into _trainingDataView. For this we are using _mlContext and location that is also passed into the constructor.
| public Model(MLContext mlContext, IEstimator<ITransformer> algorythm, string trainingDataLocation) | |
| { | |
| _mlContext = mlContext; | |
| _algorythim = algorythm; | |
| _trainingDataView = _mlContext.Data.LoadFromTextFile<BikeSharingDemandSample>( | |
| path: trainingDataLocation, | |
| hasHeader: true, | |
| separatorChar: ','); | |
| Name = algorythm.GetType().ToString().Split('.').Last(); | |
| } |
This brings us to an important function called BuildAndFit. Here it is once again so we can explore its main parts:
| public void BuildAndFit() | |
| { | |
| var pipeline = _mlContext.Transforms.CopyColumns(inputColumnName: "Count", outputColumnName: "Label") | |
| .Append(_mlContext.Transforms.Categorical.OneHotEncoding("Season")) | |
| .Append(_mlContext.Transforms.Categorical.OneHotEncoding("Year")) | |
| .Append(_mlContext.Transforms.Categorical.OneHotEncoding("Holiday")) | |
| .Append(_mlContext.Transforms.Categorical.OneHotEncoding("Weather")) | |
| .Append(_mlContext.Transforms.Concatenate("Features", | |
| "Season", | |
| "Year", | |
| "Month", | |
| "Hour", | |
| "Weekday", | |
| "Weather", | |
| "Temperature", | |
| "Humidity", | |
| "Windspeed", | |
| "Casual")) | |
| .Append(_mlContext.Transforms.NormalizeMinMax("Features", "Features")) | |
| .AppendCacheCheckpoint(_mlContext) | |
| .Append(_algorythim); | |
| _trainedModel = pipeline.Fit(_trainingDataView); | |
| _predictionEngine = _mlContext.Model.CreatePredictionEngine<BikeSharingDemandSample, BikeSharingDemandPrediction>(_trainedModel); | |
| } |
This is the most important function of Model class, since this is the place where we build machine learning model and utilize supervised learning. We store our model into pipeline variable and use _mlContext to build it. First we need to preprocess data (something we have learned from data analysis), so we use Transform from MLContext to handle categorical data and put data into the same scale. Also we mark input features as such and add desired algorithm in the end of the pipeline.
Then we call Fit method of the pipeline and pass the data that is stored in _trainingDataView. This is where our model is getting trained. This term – fit, comes from the data science terminology. It means that we fit our model to the needs of our data. The output of this operation is trained model which is later used for creation of prediction engine.
Other functions of the Model class are pretty straight forward, but let’s check them out:
| public BikeSharingDemandPrediction Predict(BikeSharingDemandSample sample) | |
| { | |
| return _predictionEngine.Predict(sample); | |
| } | |
| public RegressionMetrics Evaluate(string testDataLocation) | |
| { | |
| var testDataView = _mlContext.Data.LoadFromTextFile<BikeSharingDemandSample>( | |
| path: testDataLocation, | |
| hasHeader: true, | |
| separatorChar: ',', | |
| allowQuoting: true, | |
| allowSparse: false); | |
| var predictions = _trainedModel.Transform(testDataView); | |
| return _mlContext.Regression.Evaluate(predictions, "Label", "Score"); | |
| } | |
| public void SaveModel() | |
| { | |
| _mlContext.Model.Save(_trainedModel, _trainingDataView.Schema, "./BikeSharingDemandsModel.zip"); | |
| } |
Predict and SaveModel methods are just simple wrappers for the MLContext functionalities. In Evaluate method, we load other set of data prepared for testing. We make predictions using trained model and function Transform and then we compare those predictions with real results using _mlContext.Regression.Evaluate. This function will eventually return RegressionMetrics as a result.
Workflow
In general, all these different pieces are combined inside of Program class. The Main method handles the complete workflow of our application. Let’s check it out:
| using BikeSharingDemand.Helpers; | |
| using BikeSharingDemand.ModelNamespace; | |
| using Microsoft.ML; | |
| using System; | |
| using System.Collections.Generic; | |
| using System.Linq; | |
| namespace BikeSharingDemand | |
| { | |
| class Program | |
| { | |
| private static MLContext _mlContext = new MLContext(); | |
| private static Dictionary<Model, double> _stats = new Dictionary<Model, double>(); | |
| private static string _trainingDataLocation = @"Data/hour_train.csv"; | |
| private static string _testDataLocation = @"Data/hour_test.csv"; | |
| static void Main(string[] args) | |
| { | |
| var regressors = new List<IEstimator<ITransformer>>() | |
| { | |
| _mlContext.Regression.Trainers.Sdca(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.LbfgsPoissonRegression(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.FastForest(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.FastTree(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.FastTreeTweedie(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.Gam(labelColumnName: "Count", featureColumnName: "Features") | |
| }; | |
| regressors.ForEach(RunAlgorythm); | |
| var bestModel = _stats.Where(x => x.Value == _stats.Max(y => y.Value)).Single().Key; | |
| VisualizeTenPredictionsForTheModel(bestModel); | |
| bestModel.SaveModel(); | |
| Console.ReadLine(); | |
| } | |
| private static void RunAlgorythm(IEstimator<ITransformer> algorythm) | |
| { | |
| var model = new Model(_mlContext, algorythm, _trainingDataLocation); | |
| model.BuildAndFit(); | |
| PrintAndStoreMetrics(model); | |
| } | |
| private static void PrintAndStoreMetrics(Model model) | |
| { | |
| var metrics = model.Evaluate(_testDataLocation); | |
| Console.WriteLine($"*************************************************"); | |
| Console.WriteLine($"* Metrics for {model.Name} "); | |
| Console.WriteLine($"*————————————————"); | |
| Console.WriteLine($"* R2 Score: {metrics.RSquared:#.##}"); | |
| Console.WriteLine($"* Mean Absolute Error: {metrics.MeanAbsoluteError:#.##}"); | |
| Console.WriteLine($"* Mean Squared Error: {metrics.MeanSquaredError:#.##}"); | |
| Console.WriteLine($"* RMS Error: {metrics.RootMeanSquaredError:#.##}"); | |
| Console.WriteLine($"*************************************************"); | |
| _stats.Add(model, metrics.RSquared); | |
| } | |
| private static void VisualizeTenPredictionsForTheModel(Model model) | |
| { | |
| Console.WriteLine($"*************************************************"); | |
| Console.WriteLine($"* BEST MODEL IS: {model.Name}!"); | |
| Console.WriteLine($"* Here are its predictions: "); | |
| var testData = new BikeSharingDemandsCsvReader().GetDataFromCsv(_testDataLocation).ToList(); | |
| for (int i = 0; i < 10; i++) | |
| { | |
| var prediction = model.Predict(testData[i]); | |
| Console.WriteLine($"*————————————————"); | |
| Console.WriteLine($"* Predicted : {prediction.Score}"); | |
| Console.WriteLine($"* Actual: {testData[i].Count}"); | |
| Console.WriteLine($"*————————————————"); | |
| } | |
| Console.WriteLine($"*************************************************"); | |
| } | |
| } | |
| } |
We have three helper methods here which we should explain before going through the Main method. RunAlgorythm method receives information about the used algorithm and creates a new Model object. Then it calls BuildAndFit method and passes the location to the testing data set. Finally, it calls PrintAndStoreMetrics.
Inside of PrintAndStoreMetrics few things are done. Evaluate method of the Model object is called and returned metrics are printed. We print few metrics:
- R2 Score
- Absolute loss
- Squared loss
- Root Square Mean loss
Also, this method stores metrics values so we can find out which algorithm performed the best. VisualizeTenPredictionsForTheModel is used to print ten predictions from the algorithm that gave the best results. Finally, we can explore Main method:
| static void Main(string[] args) | |
| { | |
| var regressors = new List<IEstimator<ITransformer>>() | |
| { | |
| _mlContext.Regression.Trainers.Sdca(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.LbfgsPoissonRegression(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.FastForest(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.FastTree(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.FastTreeTweedie(labelColumnName: "Count", featureColumnName: "Features"), | |
| _mlContext.Regression.Trainers.Gam(labelColumnName: "Count", featureColumnName: "Features") | |
| }; | |
| regressors.ForEach(RunAlgorythm); | |
| var bestModel = _stats.Where(x => x.Value == _stats.Max(y => y.Value)).Single().Key; | |
| VisualizeTenPredictionsForTheModel(bestModel); | |
| bestModel.SaveModel(); | |
| Console.ReadLine(); | |
| } |
Inside of the regressors variable, the list of all algorithms that are used is stored. On each of these algorithms, we call RunAlgorythm method. It will create the model, train it and call PrintAndStoreMetrics method. This method will do the evaluation and store the metrics. Based on this information (R2 score), we will detect the best model, call VisualizeTenPredictionsForTheModel and finally save it.
Results
Here is the output of the code:
Metrics for SdcaRegressionTrainer *------------------------------------------------ R2 Score: .54 Mean Absolute Error: 105.73 Mean Squared Error: 22297.6 RMS Error: 149.32 Metrics for LbfgsPoissonRegressionTrainer *------------------------------------------------ R2 Score: .38 Mean Absolute Error: 117.09 Mean Squared Error: 29808.61 RMS Error: 172.65 Metrics for FastForestRegressionTrainer *------------------------------------------------ R2 Score: .73 Mean Absolute Error: 76.94 Mean Squared Error: 12957.68 RMS Error: 113.83 Metrics for FastTreeRegressionTrainer *------------------------------------------------ R2 Score: .93 Mean Absolute Error: 38.04 Mean Squared Error: 3145.39 RMS Error: 56.08 Metrics for FastTreeTweedieTrainer *------------------------------------------------ R2 Score: .94 Mean Absolute Error: 35.52 Mean Squared Error: 2885.69 RMS Error: 53.72 Metrics for GamRegressionTrainer *------------------------------------------------ R2 Score: .73 Mean Absolute Error: 81.94 Mean Squared Error: 13261.17 RMS Error: 115.16 BEST MODEL IS: FastTreeTweedieTrainer! Here are its predictions: *------------------------------------------------ Predicted : 226.6278 Actual: 205 *------------------------------------------------ *------------------------------------------------ Predicted : 280.0654 Actual: 260 *------------------------------------------------ *------------------------------------------------ Predicted : 325.1689 Actual: 277 *------------------------------------------------ *------------------------------------------------ Predicted : 276.9632 Actual: 281 *------------------------------------------------ *------------------------------------------------ Predicted : 296.31 Actual: 247 *------------------------------------------------ *------------------------------------------------ Predicted : 254.7126 Actual: 267 *------------------------------------------------ *------------------------------------------------ Predicted : 436.1084 Actual: 417 *------------------------------------------------ *------------------------------------------------ Predicted : 746.1508 Actual: 810 *------------------------------------------------ *------------------------------------------------ Predicted : 777.2223 Actual: 811 *------------------------------------------------ *------------------------------------------------ Predicted : 587.1061 Actual: 623 *------------------------------------------------
As you can see, we got the best results with FastTreeTweedie algorithm which had R2 score – 0.88 and the absolute loss – 49.48.
Using Model Builder

Another way that we can do this is by using Model Builder. This is graphical Visual Studio extension to build, train, and deploy custom machine learning models. You can download it from here and install in your Visual Studio. It is very simple to use as you can see from the instructions. Let’s apply that process and see where we land.
First we click the right click on our project, go to Add and then to Machine learning:
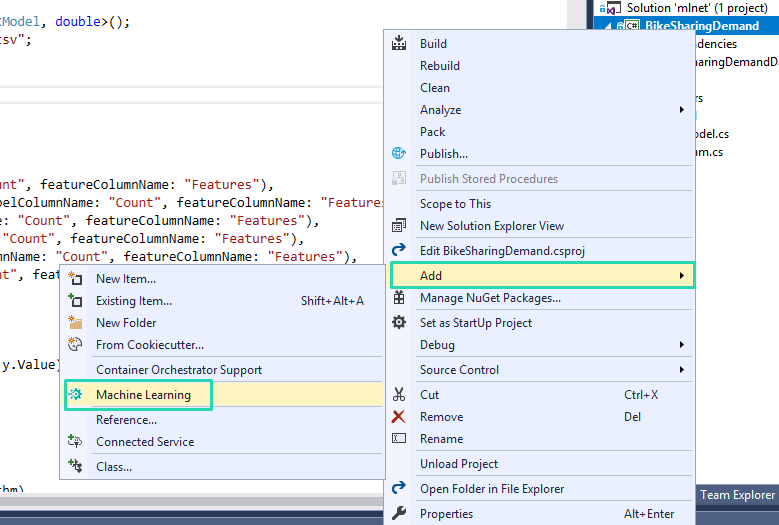
This will open window in which we need to pick scenario. We are picking Price Prediction, meaning regression scenario:

Once this is selected, we need to pick a source of the training data. In this example, that is .csv file, but this can be a database as well.

Then we need to enter training time and start the training process:

Once the training is complete we can proceed with evaluation:
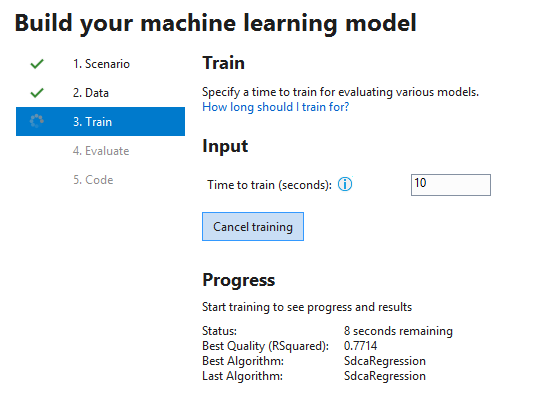
Here, we can see how different algorithms performed on our data:

Then we can generate the code:

This seems awful lot like the thing we just did, right? If you take a look at the code, you will see that these algorithm that is used is FastTreeRegression. The difference is that some of it’s parameters are tweaked:
| // Set the training algorithm | |
| var trainer = mlContext.Regression.Trainers.FastTree( | |
| new FastTreeRegressionTrainer.Options() { | |
| NumberOfLeaves = 98, | |
| MinimumExampleCountPerLeaf = 10, | |
| NumberOfTrees = 500, | |
| LearningRate = 0.07655732f, | |
| Shrinkage = 0.2687001f, | |
| LabelColumnName = "season", | |
| FeatureColumnName = "Features" | |
| }); |
Conclusion
In this big article, we went through machine learning basics and we learned how to use ML.NET to build our own machine learning models. We had a chance to explore one regression problem and solve them using different approaches. What we haven’t do and where you can go from here, is exploring every algorithm we used here. Every algorithm can be tuned and you can get better results like that. Apart from that, there is so much more to the whole machine learning field that we were able to present here. However, I hope that this is a good starting point for any C# developer who wants to get into machine learning.
Thank you for reading!
Read more posts from the author at Rubik’s Code.


Trackbacks/Pingbacks